
In the world of artificial intelligence, speech recognition is making great strides. But what about Quebec French, that lively, colorful and sometimes elusive language for the big language models?
This is the question tackled by the test bed project piloted by data scientist Amira Morsli and Gilles Boulianne, Scientific Director and Practice Leader, Speech.
This internal CRIM project, funded in part by NSERC, aims to evaluate and improve the performance of speech recognition models on spontaneous Quebec French.
The work was divided into two consecutive projects, with Amira Morsli in charge of the first. The results of the second project, whose main work was carried out by Coralie Serrand, had not yet been published at the time of writing.
Why a test bench?
“We often hear that solutions from Google or Microsoft work less well in Quebec, but we didn’t have any proof,” explains Gilles Boulianne.
The idea therefore arose to create a testbed capable of integrating and testing different models – whether proprietary, open source or locally developed – on an authentic corpus of spontaneous Quebecois French, built up thanks to the work of Amira Morsli.
“Most systems cover around 100 languages, but there are over 7000. The question then becomes how to include dialects, regional accents or local varieties,” explains Amira Morsli.
This test bed measures not only the error rate of the models, but also their execution speed, memory consumption and, above all, their ability to preserve the meaning of words despite errors. “Counting word errors is all very well, but if the meaning is preserved, the impact is less,” emphasizes Gilles Boulianne.
A demanding collection and alignment process
Creating the corpus was a real challenge.
Amira Morsli explains: “We transformed videos into audio, then extracted and cleaned up the PDF transcripts, often from public commissions such as Bastarache and Charbonneau. We had to align each audio segment with its text and speaker, a long and iterative process. This corpus, rich in accents and emotions, reflects the diversity of Quebec French, even if the lack of demographic annotations makes it difficult to measure its variety precisely.
A scientific and sociolinguistic challenge
Why the interest in Quebec French? Because, as Gilles Boulianne points out, there is little data available to train models, unlike for English or international French. Multilingual models therefore struggle to recognize Quebecois, which limits their usefulness for local users and businesses.
The project also aims to inspire the scientific community. “We hope that other researchers will use and enrich the corpus, for speech recognition, but also for sociolinguistic studies,” explains Gilles Boulianne. The dream? One day, to see the emergence of a Quebec foundation model capable of understanding and speaking with a local accent, as is the case in Iceland and elsewhere.
Recognition at Interspeech 2025
It was against this backdrop that the results of the first project were presented at Interspeech 2025, the largest international conference dedicated to speech and language research, held from August 17 to 21 in Rotterdam, the Netherlands. The theme of this 26th edition was “Fair and Inclusive Speech Science and Technology”, focusing on linguistic and individual diversity as a source of richness for more equitable, robust and personalized speech technologies.
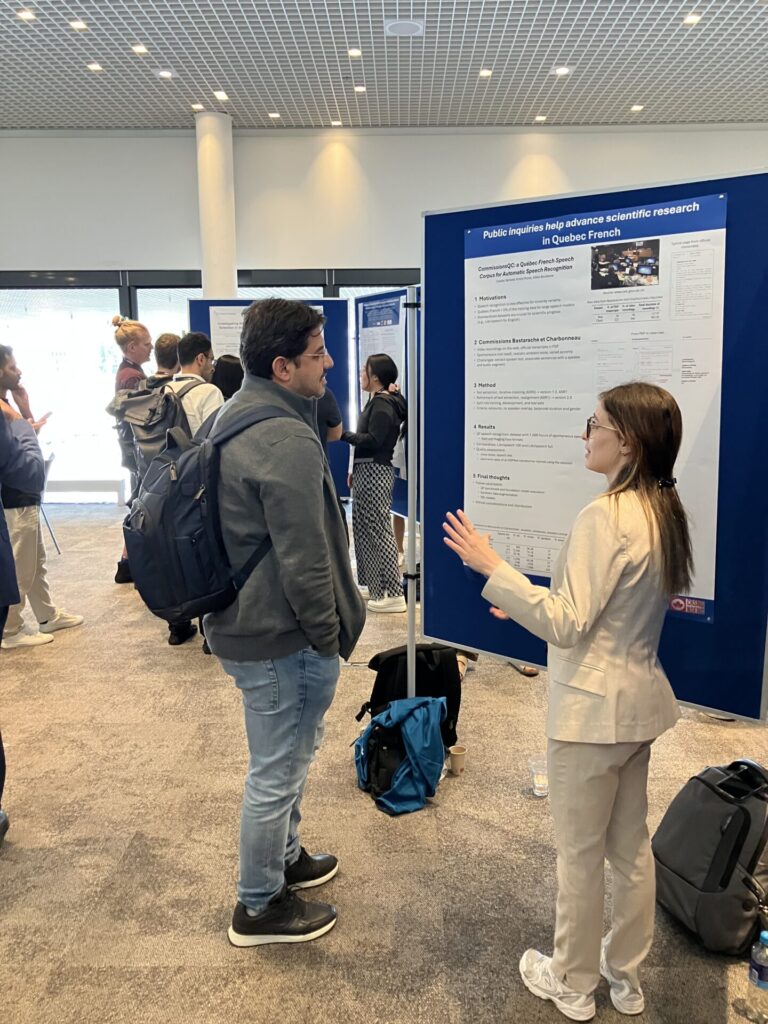
For four days, thousands of researchers, students and professionals gathered to attend plenary lectures, oral sessions and poster presentations. “There were parallel sessions all day long, exciting exchanges and a real buzz around innovative projects,” says Gilles Boulianne.
Amira Morsli, who presented the project, remembers the interest generated. “People wanted to know how to reproduce our work, in other languages or contexts. Some even offered to collaborate to enrich the corpus.”
A human and professional adventure
For Amira Morsli, this was a landmark professional project. “It was my first internship in Canada and my first international conference. I learned to love Quebecois and understand its expressions”.
Gilles Boulianne also sees a reconnection with the “science of speech”, beyond neural networks and language models.
Le banc d’essai de grands modèles de parole en français québécois spontané is much more than a technical tool. It’s an invitation to recognize the richness and complexity of languages, to value them in the digital ecosystem and to dream about the future of this promising project, which we’ll be following closely.



