

Cet article est uniquement disponible en anglais.
In August 2021, a PR aimed at adding a SOTA architecture (namely EfficientNet) to TorchVision, a Python-based PyTorch package for computer vision experiments, was submitted on GitHub. Even though deep learning practitioners are used to testing new architectures that are regularly posted on this platform, this is certainly a welcome contribution. On the other hand, C++ contributions to PyTorch (or more precisely to LibTorch, which is PyTorch’s C++ API) and TorchVision from the official maintainers are limited, particularly for independent contributors, so the need for new contributions is even greater.
This post describes the C++ implementation of a pair of recent architectures, EfficientNet and NFNet, as well as a testing tool that uses these architectures. The whole package is available on GitHub.
The proposed package represents a wider pedagogical contribution aimed at providing a concrete example of development of a training pipeline using LibTorch.
Implementing EfficientNet
In 2019, researchers from Google Brain used neural architecture search to design a new baseline network called B0, whose scalable properties (width, depth, image resolution) allow the creation of a family of models (from B1 through B7) called EfficientNets. They define a compound parameter alpha that helps determine the depth and input resolution of the most appropriate architecture with respect to available resources, while also setting the width of the convolutional filters layers making up each layer.
The architecture consists of 9 stages, each of which being made of 1 to 4 layers (thick blue rectangles in the Figure below), where a layer is either a convolutional layer or a series of “mobile inverted bottleneck blocks” (MBConv blocks). The term MBConv6 means that six of those blocks make up that particular layer. Note the stride error flagged by the red rectangle (28x28x80 should be 14x14x80, see https://github.com/lukemelas/EfficientNet-PyTorch/issues/13).
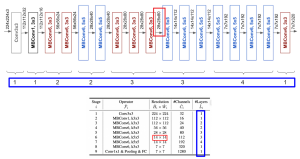
This C++ Implementation of the architecture with LibTorch closely follows Lukemelas’ PyTorch implementation. At the time of writing, the swish() activation function wasn’t available in LibTorch, so a basic implementation is provided in the source code.
Implementing NFNet and Gradient Clipp
The NFNet family of architectures has attracted a lot of attention recently due to its SOTA performance on the ImageNet dataset while avoiding the use of batch normalization. To do so, the authors draw not only on their previous work on Normalizer-Free ResNets, but they also make a number of contributions in order to stabilize and optimize the new architecture:
- Normalization of the weights of the convolutional layers
- Use of SE-ResNeXt-D as baseline and improvement to their width/depth patterns
- Adoption of a scaling strategy to adapt the baseline to different compute budgets
- Use of a gradient clipping strategy to stabilize training when large batch sizes are used
Again, the proposed C++ implementation of NFNet and its variants is a ‘translation’ of a PyTorch implementation available on GitHub. In order to provide the new optimizer with the above-mentioned gradient clipping strategy, instead of doing Python-C++ translation, the C++ source code of the SGD optimizer was cloned and modified accordingly.
Training Pipeline
The code base features a fairly complete training loop that includes a data loader and data augmentation functions. The training loop has been put to test with the ImageNet dataset. Whether the proposed source code is generic enough for all types of image classification projects remains to be seen; yet it is another example of how LibTorch objects and components can be used in a practical application (beyond toy examples found on the Internet).
Training Loop
The main training loop is defined here. When using LibTorch, it is important to take into account that many functions are defined using templates, as presented below.

For instance, the reference sample training loop takes a generic DataLoader, which will be compiled with the specific data loader and sampler implementations that were specified to execute training, as detailed here.
Using a custom DataAugmentationDataset implementation (located here), the complete instantiation of the data loader employed by the templated training loop can be summarized with the code snippet below. In that particular example, a random sampler is employed to pick images and labels from the dataset of samples that get augmented by the selected DataLoader. Due to the use of the templating approach, it is easy to modify only the “data loading” portion of the code if one wants to explore another approach, without affecting the training loop itself.

This makes the training loop versatile for any implementation of the data loading procedure, either adapted for different dataset annotation formats or loading strategies, as long as templating dependencies are respected. Class interfaces are also employed as function inputs to the training loop (see torch::nn::AnyModule and torch::optim::Optimizer of the first code snippet) to allow switching between different model and optimizer implementations.
The training loop itself contains a top-level iteration of the requested amount of epochs, for which the whole training and validation sets get iterated, each with nested loops of batch samples. Within the train set loop, each batch processes forward pass predictions and computes backpropagation of gradients according to the obtained loss against label annotations. In the proposed implementation, NLL Loss is employed in combination with Softmax, although many more loss functions are available since LibTorch 1.4.0. Model weights are updated using the computed gradients based on this loss and the configured optimizer step, which defines learning-rate and other hyperparameters based on its algorithm. This process is presented in the following code snippet.

The validation batch loop does essentially the same forward pass to obtain model predictions, but counts the number of correct and incorrect predictions against labels instead of updating weights. Following each epoch iteration, the model weights are saved in a checkpoint file, and the best model is updated when accuracy improves over previous epochs.
Data Augmentation
The data augmentation code is a fork of a GitHub project that has been directly integrated in the source code. It includes basic data augmentation operations such as image resizing, rotations, reflections, translations, noise injection, etc. with randomness. All these operations help generate training data with small variations. This helps the model to generalize and be more robust against small changes within images, in order for inference to produce consistent predictions when presented with new images that can contain similar variations. It also reduces the chances of overfitting.
Data augmentation is applied inline when loading samples within the training loop, using the data loader iterator.

This iterator retrieves each sample image and its associated label by loading it from file, augmenting it randomly and returning it following normalization using the function here. Note that the proposed implementation uses normalization mean and standard deviation from ImageNet specifically, and should be adjusted accordingly when using other datasets.
Building and Testing the Pipeline
Because the main training loop offers flexibility over the selected model, optimizer and data loader, this C++ implementation uses the CLI11 library to create a command line interface that eases this parametrization as an utility that can be called from the shell. The TestBench main function allows the user to specify many options, which are used to instantiate the relevant models, optimizers, data loader paths and other configuration parameters. This is where the most important distinction against most toy example codes found online can be observed. The code does not make use of specific hardcoded model, optimizer or hyperparameters definitions. Instead, the implementation presents how abstract classes and interfaces can be employed to develop a flexible and extendable test utility. As a result, users can extend the testing pipeline as needed by adding new model or optimizer implementations and rapidly training them without having to directly adjust the training loop.
Conclusion
This post described an effort to contribute to LibTorch, including implementation of new architectures and a code base that makes use of this library. The main goal was to show how to instantiate these architectures and use them in a fairly feature-complete training loop. Hopefully, developers faced with the challenge of implementing deep learning training loops in C++ will find this code useful.









