

Ce billet représente le fruit d’une veille technologique préalable à la construction d’une application Web de vidéoconférence basée sur une architecture moderne et utilisant les technologies disponibles en ce printemps 2018.
Nous entendons par «applications Web» une application ne nécessitant aucune installation supplémentaire et respectant les derniers standards Web recommandés par le W3C. Cela exclut donc, par exemple, une technologie nécessitant l’installation d’un plugin Flash dans le navigateur.
Ceci est l’histoire, plutôt technique mais tout de même accessible, d’une petite aventure dans l’univers WebRTC de la vidéoconférence Web.

Les protocoles de diffusion vidéo
Nos premières recherches nous ont rapidement amenés vers les protocoles de diffusion vidéo et la notion de diffusion en direct (live streaming). Après tout, ne cherchions-nous pas nous aussi à partager en direct du contenu audio/vidéo dans un lecteur vidéo HTML5?
Note. Pour un tour d’horizon de ces technologies, voir ce rapport encore tout à fait pertinent: État de l’art des technologies et protocoles de diffusion de contenu vidéo sur Internet
Les protocoles HLS (pour HTTP Live Streaming), MPEG-DASH (Dynamic Adaptative Streaming over HTTP) ou encore HDS (HTTP Dynamic Streaming) existent pour accomplir cette tâche. Le débat est encore en cours à savoir lequel sélectionner pour une diffusion en direct de contenu vidéo.
En réalité, bien qu’on parle de diffusion en direct, ces protocoles impliquent une latence de niveau intermédiaire puisqu’ils sont tous basés sur HTTP, lui-même basé sur TCP/IP. Avec HLS ou MPEG-DASH, par exemple, on aura un écart de l’ordre de 30 à 45 secondes entre la captation du flux multimédia et l’écoute de celui-ci dans le navigateur! Cet écart pourrait être éventuellement réduit sous les 10 secondes en utilisant différentes techniques d’optimisation (voir Achieving low latency video streaming).
Note. Il existe aussi d’autres protocoles comme RTMP qui n’est pas basé sur HTTP et offre une faible latence, mais qui nécessite un plugin Flash pour être utilisé dans un navigateur, ce qui l’exclut d’office.
Une latence de plusieurs secondes est, par ailleurs, inimaginable dans un contexte de vidéoconférence et c’est pour cette raison qu’il faut irrémédiablement se tourner vers des diffusions à ultra-faible latence, des diffusions en temps réel.
Au-delà de la latence, la diffusion en direct est un cas d’utilisation distinct du nôtre en ce qu’elle est, par nature, unidirectionnelle et implique souvent la diffusion à une large audience… Bon, il s’agit certainement d’un mauvais départ et vous êtes probablement aussi confus que nous…

Et si on prenait un peu de recul pour mieux comprendre les enjeux?
Communication temps-réel dans le navigateur
Dans un monde pas si lointain, toute fonctionnalité interactive ou encore tout traitement intensif côté client dans un navigateur passaient par l’intermédiaire de plugins: Java Applet ou encore Flash (particulièrement pour l’affichage de contenu vidéo). Ces plugins étaient aussi un mal nécessaire pour pouvoir utiliser les différents protocoles de communication ou autres standards propres au monde de l’Internet.
Dans le monde plus particulier de la communication temps-réel, hier encore, l’installation d’un logiciel propriétaire (WebEx, Zoom) était nécessaire pour initier une communication multimédia en temps réel. Dans le monde du Web, le plugin Flash permit de remédier temporairement à cette situation en offrant l’interopérabilité dont tous rêvaient et en élargissant les possibilités permises dans le navigateur Web. Mais Flash appartenait à une seule compagnie, son développement n’était ni concerté ni ouvert et cette technologie opérait dans un navigateur Web, tel un corps étranger, par intermédiaire de l’installation d’un plugin.
Or, depuis l’avènement du standard HTML5, l’idée, et la tendance générale, est d’apporter les fonctionnalités directement dans le navigateur et d’instaurer des API réellement natives (du point de vue du navigateur) et développées de façon collaborative et ouverte par les acteurs de l’industrie.
Ainsi naquit la spécification WebRTC
La spécification WebRTC

WebRTC pour Web Real-Time Communication entend, comme son nom l’indique, rendre possible les communications multimédias en temps réel dans un contexte Web en évacuant la nécessité d’une installation préalable. WebRTC est une collection de standards, de protocoles et d’API JavaScript permettant le partage navigateur à navigateur de contenu vidéo, audio ou encore de données.
Ce standard fut défini conjointement par le W3C Working Group, qui se chargea de la définition des API dans le navigateur, et l’IETF Working Group, qui s’occupa des aspects plus techniques des protocoles d’échange, du format des données, de la sécurité, etc.
WebRTC se compose de trois API principales — MediaStream, RTCPeerConnection, DataChannel — et nécessite quelques protocoles de transport que nous verrons dans cette section.
MediaStream
Un critère essentiel pour que le navigateur puisse offrir des fonctionnalités de téléconférence est évidemment de pouvoir accéder au contenu audio/vidéo capturé par l’appareil hôte.
L’objet MediaStream permet un tel accès simplifié par la méthode getUserMedia, mais encapsule aussi de puissants moteurs de traitement audio/vidéo internes permettant d’en améliorer la qualité (encodage, décodage, synchronisation, gestion des fluctuations de la bande passante, dissimulation des paquets perdus, réduction des bruits dans la bande audio, amélioration de l’image dans le flux vidéo, etc.) Notons que la majorité des navigateurs vont forcer l’utilisation de HTTPS dans la page avant de permettre l’utilisation de getUserMedia.
WebRTC supporte présentement différents codecs de compression, mais principalement VP8 et H.264 pour la vidéo et Opus pour l’audio.
Une fois l’acquisition du flux multimédia enclenché, celui-ci peut être utilisé à différentes fins dans d’autres API du navigateur: Web Audio pour lancer la piste audio dans le navigateur, Canvas pour faire la capture d’une image, CSS3 et WebGL pour appliquer des effets 2D/3D sur le flux ou encore RTCPeerConnection, que nous verrons plus loin, pour envoyer directement ces données à un autre navigateur!
Transport et protocoles
WebRTC se distingue d’abord par le choix du protocole de transport qui le soutient. En effet, WebRTC a déterminé UDP comme couche de transport (du modèle OSI) qui se prête particulièrement bien au contexte temps-réel où la latence devient critique. Si UDP n’offre aucune garantie par rapport à TCP (qui garantit l’arrivée des paquets, mais aussi l’ordre de ceux-ci), il se prête beaucoup mieux aux flux multimédias en temps réel qui peuvent généralement supporter la perte de certaines données (codecs audio et vidéo).
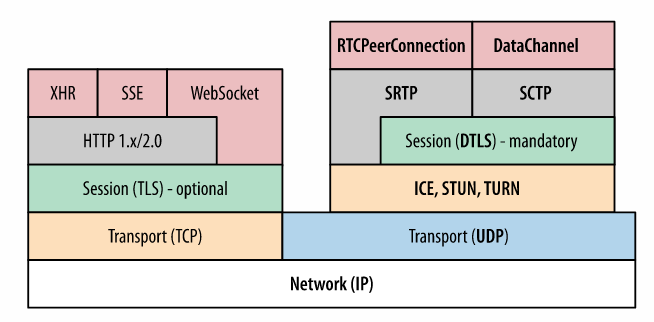
Comme le diagramme précédant en témoigne, d’autres protocoles sont mis en oeuvre pour permettre notamment le cryptage du contenu, mais aussi le contrôle du débit, le contrôle de la congestion, la gestion des erreurs, etc., tous nécessaires pour éviter la submersion du réseau et la dégradation de la communication:
- DLTS est utilisé comme couche obligatoire de sécurité et de cryptage
- SRTP est le protocole utilisé pour le transport des flux audio/vidéo
- SCTP est utilisé comme transport des autres données applicatives
Enfin, nous expliquerons plus en détail plus tard la signification de la couche ICE/STUN/TURN qui mérite d’être approfondie.
DataChannel
Cette API permet l’échange de données arbitraires (textuelles ou binaires) entre navigateurs et est entièrement dépendante de l’objet RTCPeerConnection en ce qu’elle nécessite une connexion déjà ouverte. C’est réellement l’équivalent de WebSocket, mais cette fois-ci entre deux pairs et à quelques différences près: la session d’échange peut être initiée par l’une ou l’autre des parties prenantes et la méthode de livraison des paquets et la fiabilité de celle-ci est configurable (au moyen de SCTP).
RTCPeerConnection
L’API RTCPeerConnection est responsable de la communication des contenus audio et vidéo et devient donc fondamentale dans le cas qui nous intéresse. C’est par cette interface que deux pairs vont apprendre à communiquer ensemble et vont établir un tunnel de partage de contenu multimédia (par SRTP).
RTCPeerConnection s’occupe des étapes d’initialisation de la connexion entre les pairs, la gestion de la session, l’envoi des flux multimédias et l’état de la communication.

L‘initialisation de la communication: la pièce manquante
Malheureusement, la connexion de deux pairs par l’intermédiaire d’un navigateur n’est pas aussi simple que notre dernier graphique le laisse entendre. Quelques étapes sont encore nécessaires tels que l’initialisation d’une telle connexion!

Volontairement exclue de la spécification WebRTC, l’initialisation de la communication (ou signaling) est le chaînon manquant sans lequel vos fureteurs ne pourront pas communiquer directement ensemble. Cette initialisation nécessaire à RTCPeerConnection requiert impérativement un serveur distant qui va servir d’intermédiaire aux différents participants. L’initialisation se résume à l’authentification des participants et à l’échange d’informations nécessaires à la localisation des multiples participants (adresse IP, port, SDP local, etc.).
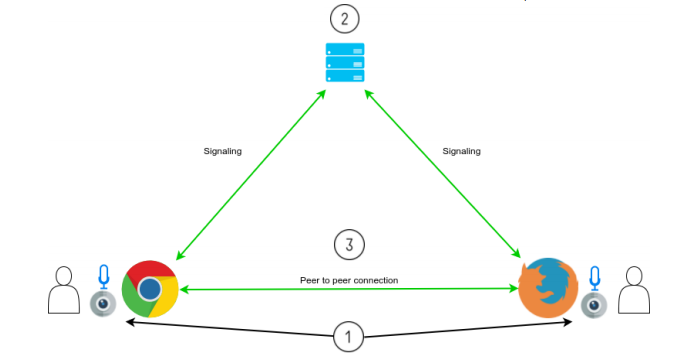
- Le navigateur obtient l’accès au matériel d’enregistrement comme la caméra ou le microphone.
- Chaque participant s’identifie et échange l’information nécessaire à l’établissement d’une connexion avec les autres participants.
- Chaque participant peut maintenant partager directement son contenu multimédia avec les autres participants et la communication peut alors commencer.
Étant exclus de la spécification, plusieurs protocoles concurrents d’initialisation sont utilisés dans le contexte WebRTC tel que SIP, XMPP, Socket.IO ou encore différents protocoles personnalisés et/ou propriétaires (les fournisseurs de PaaS par exemple). Si WebSocket est généralement utilisé comme transport pour ces protocoles (de par sa nature bidirectionnelle) d’autres méthodes peuvent aussi être utilisées comme XHR/Comet, SSE, HTTP/2 ou encore la fameuse ficelle pour les plus nostalgiques.

Une pluralité de solutions existe donc pour l’initialisation et ces solutions sont plutôt équivalentes ou ne représentent pas nécessairement un grand enjeu. Une fois l’initialisation complétée, le serveur intermédiaire ne sera théoriquement plus requis pour la suite de la communication.
Si on peut croire que la communication pourrait enfin avoir lieu, détrompez-vous, le réseau Internet entend nous offrir encore quelques surprises…
La réalité du monde d’Internet et les serveurs ICE (STUN/TURN)

Le réseau Internet est en fait constitué de plusieurs millions de réseaux publics et privés reliés par de nombreux câbles, routeurs et une panoplie d’autres dispositifs comme des pare-feu ou encore des routeurs NAT (Network Address Translation) ainsi que différentes restrictions déterminées par votre fournisseur de service Internet (ISP).
La majorité des appareils disposent d’une adresse IP privée (adresse non unique d’un point de vue global) et nécessite un dispositif NAT qui s’occupe de transformer l’adresse privée en adresse publique (ainsi que les ports) pour pouvoir accéder à l’Internet. En réalité, dans la grande majorité des cas, deux fureteurs ne pourront tout simplement pas communiquer directement ensemble puisqu’aucun des deux ne connaît l’adresse IP et le port qu’il peut utiliser pour atteindre l’autre.
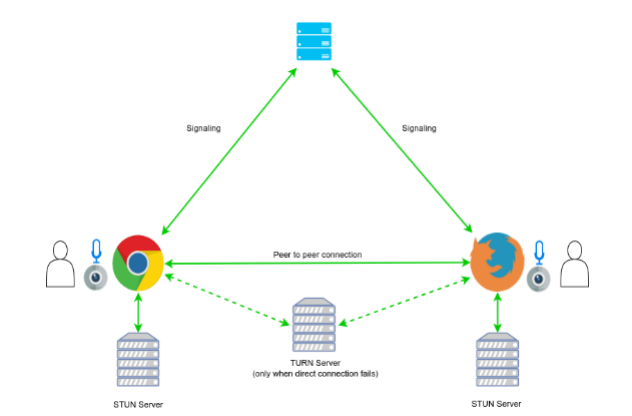
C’est ici que la technique ICE (Interactive Connectivity Establishment) intervient pour permettre aux agents WebRTC de communiquer en faisant abstraction de la complexité des réseaux formant la réalité d’Internet. ICE va utiliser des serveurs Session Traversal Utilities for NAT (STUN) et Traversal Using Relays around NAT (TURN) pour palier aux problèmes causés par les pare-feu, les routeurs NAT et autres restrictions potentielles.
Un serveur STUN permet à l’agent de connaître les informations réseaux qu’il expose à l’externe, soit son adresse IP publique, le port, mais aussi le type de routeur NAT devant lui. Un tel serveur est en quelque sorte l’équivalent du site Web bien connu https://www.whatismyip.com/.
Un serveur TURN est une extension à STUN lorsque celui-ci ne parvient pas à établir la connexion. Il va permettre de relayer le média d’un agent à l’autre et devra être présent durant toute la communication contrairement à STUN. TURN est une opération définitivement plus exigeante et la communication directe devrait en tout temps être privilégiée.
En réalité, ICE fait partie intégrante de l’étape d’initialisation de la communication et voici à quoi ressemble notre nouvelle architecture après avoir ajouté nos serveurs STUN et TURN:
Différents niveaux de solutions s’offrent à vous pour l’utilisation des serveurs STUN/TURN à savoir:
- Utiliser des serveurs gratuits sur lesquels vous n’aurez aucun contrôle (https://gist.github.com/yetithefoot/7592580 pour une liste succincte)
- Souscrire à un service payant (Twilio, etc.)
- Créer votre propre serveur en utilisant par exemple une solution open source comme coturn (https://github.com/coturn/coturn) ou autre
La nature pluripartite d’une vidéoconférence
Jusqu’à maintenant nous avons vu comment connecter un pair à un autre, mais qu‘arrive-t-il lorsque que nous voulons connecter plus de participants comme dans le cas d’une vidéoconférence typique? Il existe en fait trois approches pour déployer une application de vidéoconférence pluripartite: Mesh, MCU et SFU.
L’approche Mesh
Mesh est en quelque sorte l’approche naïve, à savoir que chaque participant va envoyer son média à chacun des autres participants. Cette approche échoue rapidement au delà de 3 participants en termes de bande passante et de nombre de connexions. Un participant devra téléverser son média à chacun des autres participants et télécharger le média de chacun de ceux-ci.
C’est cette approche qui est mise en oeuvre dans la plupart des tutoriels WebRTC disponibles un peu partout sur la toile. Il s’agit d’une excellente preuve de concept, mais peu applicable à un contexte de production à moins d’en connaître expressément les limites.
Le modèle MCU
MCU pour Multiparting Conferencing Unit est l’approche dans laquelle les différents participants vont tous communiquer avec une unité centrale (un serveur) qui va s’occuper de mixer ou composer les différents flux en un seul flux audio-vidéo (en fait, quelques gabarits, mais un seul sera envoyé aux participants). C’est définitivement la meilleure approche en terme de charge sur le réseau et de nombre de connexions. Cette approche limite à une connexion entrante et sortante entre le client et le serveur, peu importe le nombre de participants.
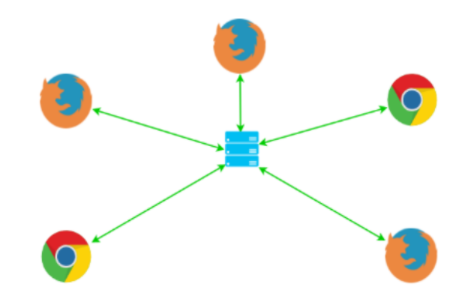
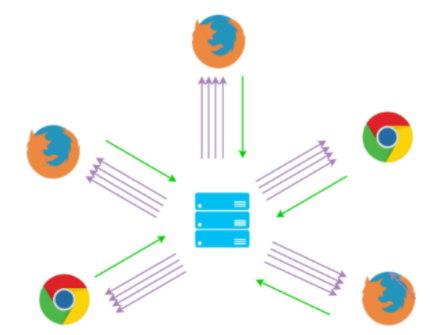
L’approche SFU
Par ailleurs, la troisième approche SFU (pour Selective Forwarding Unit) propose que chaque participant envoie son média à un serveur central qui s’occupe de le rediriger (router) aux autres participants si ceux-ci en font la demande. On limite ainsi à un le nombre de téléversement par rapport à Mesh (n participants), mais on garde le nombre de téléchargements de flux égal au nombre de participants.
Choisir le bon modèle pour votre cas d’utilisation
Si on peut croire que MCU est le modèle le plus intéressant, il faut savoir qu’un tel serveur central doit s’occuper de tous les traitements, à savoir la réception, le décodage des flux, la composition du nouveau flux, le réencodage des différents flux et l’envoi: tous des traitements extrêmement exigeants côté CPU. Plus la taille des flux vidéos augmentera (4k, mais bientôt 8k), plus ce temps de traitement croîtra largement avec cette approche et un déploiement à grande échelle basé sur le modèle MCU demande des dizaines, voire des centaines de machines supplémentaires par rapport à SFU.
En fait, c’est l’approche SFU qui est de plus en plus privilégiée dans le contexte WebRTC, quoique les différentes solutions offrent souvent des modèles hybrides. WebRTC étant multi-flux par nature, le modèle SFU s’inscrit parfaitement dans cette logique: le client reçoit de multiples flux audio et vidéo qu’il doit décoder individuellement et afficher à l’écran. SFU limite le serveur intermédiaire aux tâches simples et peu exigeantes à savoir la réception, la sélection et l’envoi des flux.
L’approche SFU pure a le désavantage d’être exigeante au niveau de la bande passante d’un participant qui doit après tout télécharger plusieurs flux. Ainsi, certaines approches SFU offrent parfois l’encodage et le décodage des contenus ne serait-ce que pour pouvoir offrir un contenu adapté aux participants (Adaptative Bitrate Streaming) et ainsi maximiser l’expérience utilisateur en limitant les interruptions.
L’autre option est d’utiliser un codec supportant l’extensibilité (H.264 SVC / Scalable VP9) ou le Simulcast pour bénéficier d’une architecture purement SFU avec l’adaptation de contenu. Dans un tel modèle SFU, chaque participant se trouve à téléverser un oignon de couches vidéo de différentes qualités et le serveur décide laquelle de ces couches sera transmise à quel participant (voir SVC and Video Communications).
Si SFU demeure le modèle privilégié du fait de ses faibles coûts de déploiement et d’exploitation par rapport à MCU, chacun des trois modèles répond adéquatement à différents cas d’utilisation. Par exemple, dans le cas de vidéoconférences se limitant à 3 voire 5 participants, le modèle Mesh peut s’avérer parfaitement adéquat. Dans un cas où les différents clients sont mobiles et disposent de peu de ressources autant au niveau CPU que de la bande-passante, MCU s’avère l’architecture optimale. Une approche hybride permet aussi de faire basculer l’application d’un modèle de type Mesh, quand un nombre minimal de participants sont connectés, à MCU/SFU lorsque le nombre passe au-delà de 4 ou 5.
Autres fonctionnalités que vous voudrez ou non
Au-delà de la possibilité d’avoir une infrastructure ayant la capacité de supporter des conférences de nature pluripartite, d’autres fonctionnalités sont aussi intéressantes et souvent disponibles dans les différents produits que nous verrons plus loin, comme:
- L’enregistrement des contenus audio et vidéo
- Qualité du contenu vidéo adapté à chaque participant
- Un système de messagerie texte
- La possibilité de pouvoir partager des fichiers
- Le partage d’écran
- La possibilité de pouvoir faire des dessins ou maquettes sous forme de whiteboard en temps réel
- La réalité augmentée (filtres, objets, etc.)
- L’intégration avec différents protocoles d’initialisation legacy (ex. SIP)
Vous devrez déterminez lesquelles de ces fonctionnalités vous seront résolument nécessaires, ou non, avant d’être à même de déterminer la bonne solution ou le bon outil pour votre application.
Solutions et outils
Que ce soit pour le choix du protocole d’initialisation en tant que tel, la mise en place des serveur ICE (STUN/TURN), le choix d’architecture ou les différentes fonctionnalités que vous entendez offrir, différentes solutions existent et faciliteront grandement le développement de votre application.
Solution purement pair-à-pair
Pour une architecture entièrement P2P (peer-to-peer), donc basée sur le modèle Mesh, vous aurez besoin de définir un protocole d’initialisation et de mettre en place les serveurs de contournement (STUN/TURN). Cette infrastructure hébergée sur place ou non sera tout de même minimale et les efforts devront être mis essentiellement dans le développement frontend de l’application.
Même dans ce contexte, il sera conseillé d’utiliser une librairie open source étant donné la volatilité actuelle et la complexité relative du standard. À ce chapitre, les différentes librairies disponibles vont simplifier l’utilisation des API MediaStream et RTCPeerConnection tout en offrant une méthode d’initialisation clé-en-main et assurant la compatibilité multi-navigateur dans l’évolution de la spécification.
Parmi les plus intéressantes à l’heure actuelle, on notera:
- simple-peer: https://github.com/feross/simple-peer
- SimpleWebRTC: https://github.com/andyet/SimpleWebRTC
- adapter.js: https://github.com/webrtc/adapter
Serveur média sur place (et open source)
Pour mettre en place une architecture MCU/SFU et disposer de multiples fonctionnalités avancées propres aux applications de vidéoconférences pluripartites, en plus de disposer du plein contrôle sur votre infrastructure, vous aurez définitivement besoin d’un serveur média.
Quelques outils semblent particulièrement se distinguer.
- Projet mature, supporté par Atlassian et bénéficiant d’une énorme communauté très active
- License: Apache 2.0
- Modèle SFU avec un signaling XMPP
- Offre beaucoup de fonctionnalités dont la messagerie, le partage d’écran (par l’intermédiaire d’un plugin), le transfert de fichiers, la suppression de bruits dans le flux audio, le cryptage des appels, etc.
- Jitsi propose aussi une application Web (React) et mobile (React Native) moderne et complète
- Connexion de participants SIP par Jigasi
- Projet open source plus ou moins abandonné en 2017 (après son acquisition par Twilio), mais le projet a repris un nouveau souffle en 2018 avec la constitution d’une nouvelle équipe de développement
- License: Apache 2.0
- Modèle hybride SFU/MCU
- Offre l’enregistrement, le transcodage, l’adaption du contenu vidéo, etc.
- Offre des librairies/SDK client pour faciliter les interactions avec le serveur (clients Java et JavaScript)
- Supporte de multiples protocoles d’initialisation
- Projet relativement nouveau basé autour d’une petite communauté
- License: ISC
- Nouvelle approche purement SFU développée avec Node.js/ES6
- Se charge de la couche multimédia seulement, donc n’inclut pas de protocole d’initialisation
- Offre du multi-flux audio/video
- Offre une librairie JavaScript client
- Pas d’enregistrement des flux et généralement peu de fonctionnalités par rapport aux autres.
Note. Les license de Janus ( GPLv3) et Medooze (GPLv2) excluaient ces produits de facto dans notre contexte, donc nous n’avons pas approfondi particulièrement ces produits.
Plateforme de communication en tant que service
Différents produits payants et offerts en tant que Communication-Platform-as-a-Service (CPaaS) existent aussi et vous offriront une infrastructure complète, stable et évolutive pour le développement de votre application de vidéoconférence basée sur WebRTC. Ces solutions offriront aussi une panoplie de fonctionnalités très avancées à la fine pointe de l’industrie.
Parmi les plus matures et utilisées, on conseillera:
Conclusion
Notre expertise dans ce domaine émergent est certainement limitée, mais il est clair, à la lecture des informations disponibles, que ces quelques petits conseils vont grandement faciliter la mise en place d’une application WebRTC de vidéoconférence:
- Munissez votre équipe de développement d’une expertise réseau
- Définissez vos cas d’utilisation et vos fonctionnalités
- Considérez longuement les différents modèles d’architecture en fonction de vos besoins
- Utilisez les outils disponibles
Et n’oubliez pas de savourer les joies de la vie!










