

This article results from a technology watch undertaken prior to building a videoconferencing web application based on modern architecture and using the technologies available in Spring 2018.
By “web application,” we mean an application that requires no additional installation and complies with the latest web standards recommended by the W3C. It excludes, for example, a technology requiring the installation of a Flash plugin in the browser.
Here is the story, on the technical side but still easy enough to follow, of a small foray into the WebRTC world of web videoconferencing.

Source: https://www.pubnub.com/wp-content/uploads/2014/10/WebRTCVoice.png
Video streaming protocols
Our initial research quickly led us to video streaming protocols and live streaming. After all, weren’t we also looking to share live audio/video content in an HTML5 video player?
Note. For an overview of these technologies, see this still very relevant report: State of the Field of Internet Video Content Delivery Technologies and Protocols.
Protocols exist to accomplish this task, including HLS (HTTP Live Streaming), MPEG-DASH (Dynamic Adaptative Streaming over HTTP) and HDS (HTTP Dynamic Streaming). The debate continues as to which one to adopt for live streaming of video content.
In reality, although we are talking about live broadcasting, these protocols imply an intermediate level of latency since they are all based on HTTP, which in turn is based on TCP/IP. With HLS or MPEG-DASH, for example, there will be a 30 to 45 seconds gap between the capture of the multimedia stream and its playback in the browser! This gap could eventually be reduced to less than 10 seconds by using different optimization techniques (see Achieving low latency video streaming).
Note. Other protocols, such as RTMP (Real Time Messaging Protocol), exist. RTMP is not based on HTTP and offers low latency, but it is ruled out because it requires a Flash plugin for use in a browser.
A latency of several seconds is, moreover, unimaginable in a videoconferencing context; for this reason, we must inevitably turn to ultra-low latency, real-time broadcasts.
Beyond latency, live streaming is distinct from our use-case in that it is, by nature, unidirectional and often involves broadcasting to a large audience. Okay, we may be off to a rocky and perhaps somewhat confusing start…

Let’s back up a little and get the big picture.
Realtime communication in the browser
In the not-so-distant past, any interactive functionality or intensive client-side processing in a browser had to be done through plugins: Java Applet or Flash (especially for video content). These plugins were also necessary when using different communication protocols or other Internet standards.
In the particular world of real-time communication, it was only yesterday that the installation of proprietary software (WebEx, Zoom) was necessary to initiate real-time multimedia communication. In the Web world, the Flash plugin temporarily resolved this issue by offering the interoperability that everyone dreamed of and expanding the capabilities permitted in the Web browser. However, Flash belonged to a single company; its development was neither concerted nor open. This technology operated in a Web browser, like a foreign body, through a plugin.
Since the advent of the HTML5 standard, the idea, and the general trend, is to bring functionalities directly into the browser and to set up APIs that are truly native (from the browser’s perspective) and that are developed collaboratively and openly by industry players.
So, the WebRTC Recommendation came to be.
The WebRTC Recommendation

WebRTC – Web Real-Time Communication – intends, as its name suggests, to make real-time multimedia communications possible in a Web context by eliminating the need for prior installation. WebRTC is a collection of standards, protocols and JavaScript APIs that allow browser-to-browser sharing of video, audio or data files.
This standard was set jointly by the W3C Working Group, responsible for defining the APIs in the browser, and the IETF Working Group, which dealt with the more technical aspects of exchange protocols, data format, security, and the like.
WebRTC consists of three main APIs – MediaStream, RTCPeerConneciton and DataChannel – and requires a few transport protocols, which we will see in this section.
MediaStream
An essential requirement for the browser to provide teleconferencing capabilities is, of course, to be able to access the audio/video content captured by the host device.
The MediaStream object allows such a simplified access through the getUserMedia method, but also encapsulates powerful internal audio/video processing engines allowing to improve the quality (encoding, decoding, synchronization, management of bandwidth fluctuations, hiding lost packets, noise reduction in the audio stream, image enhancement in the video stream, etc.). It should be noted that most browsers will force the use of HTTPS on the page before allowing the use of getUserMedia.
WebRTC currently supports various compression codecs, but mainly VP8 and H.264 for video and Opus for audio.
Once the multimedia stream is acquired, it can be used for different purposes in other APIs of the browser: Web Audio to launch the audio track in the browser, Canvas to capture an image, CSS3 and WebGL to apply 2D/3D effects on the stream or RTCPeerConnection, which we will see later, to send this data directly to another browser!
Transport protocols
WebRTC is distinguished first by the choice of the transport protocol which supports it. In effect, WebRTC has chosen UDP as the transport layer (of the OSI model), which is particularly well suited to the real-time context where latency becomes critical. Suppose UDP does not offer any guarantee compared to TCP (which guarantees the arrival of packets and the order of these packets). In that case, it lends itself much better to real-time multimedia flows, which can generally support the loss of specific data (audio and video codecs).

Web protocols on the left and WebRTC on the right.
Source: https://hpbn.co/assets/diagrams
As the previous diagram shows, other protocols are implemented to allow content encryption, but also flow control, congestion control, error management, etc., all necessary to avoid network flooding and communication degradation:
- DTLS is used as a mandatory security and encryption layer
- SRTP is the protocol used to transport audio/video streams
- SCTP is used for transporting other application data
Finally, the significance of the ICE/STUN/TURN layer, which merits some consideration, will be explained in greater detail later.
DataChannel
This API allows the exchange of arbitrary data (textual or binary) between browsers and is entirely dependent on the RTCPeerConnection object in that it requires an already open connection. It is the equivalent of WebSocket, but in this case between two peers and with a few differences: the exchange session can be initiated by either of the parties involved and the method of packet delivery, including its reliability, is configurable (through SCTP).
RTCPeerConnection
The RTCPeerConnection API is responsible for audio and video content communication and is, therefore, fundamental in the case that interests us. It is through this interface that two peers will learn to communicate with each other and will establish a tunnel for sharing multimedia content (through SRTP).
RTCPeerConnection handles the initialization of the connection between peers, the session management, the sending of multimedia streams and the communication state.

Peer-to-peer connection for multimedia content sharing
Source: WebRTC.ventures: A Guide to WebRTC — How it works Part I
Initializing communication: the missing link
Unfortunately, connecting two peers through a browser is not as simple as our last diagram might suggest. A few steps are still necessary, like initializing such a connection!

Deliberately excluded from the WebRTC specification, the initialization of the communication (or signalling) is the missing link without which your browsers cannot communicate directly. This initialization is necessary for RTCPeerConnection and requires a remote server to act as an intermediary for the different participants. The initialization is merely the authentication of participants and the exchange of information necessary to locate the participants (IP address, port, local SDP, etc.).
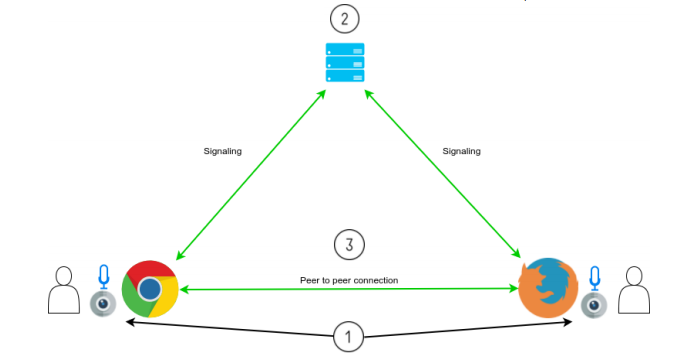
Initialization as one of three essential steps.
Source: WebRTC.ventures: How to build a video conference application using webRTC
- The navigator gets access to the recording device, such as the camera or microphone.
- Each participant identifies him/herself and exchanges the information needed to establish a connection with the other participants.
- Each participant can now share multimedia content directly with the other participants, and communication can begin.
Several competing initialization protocols excluded from the specification are used in the WebRTC framework, such as SIP, XMPP, Socket.IO or various custom or proprietary protocols (e.g. PaaS providers). While WebSocket is generally used as a transport for these protocols (due to its bidirectional nature), other methods can also be used, such as XHR/Comet, SSE, or HTTP/2.

Numerous equivalent solutions, therefore, exist for initialization, and none present any real issues. Once the initialization is completed, the passthrough server will, in theory, no longer be required for the remainder of the communication.
In theory. Because if you think that the communication can finally take place, you may be surprised by the many little surprises that await on the internet network…
The reality of the internet environment and ICE servers (STUN/TURN)

The Internet comprises millions of public and private networks connected by numerous cables, routers and a variety of other mechanisms, such as firewalls and Network Address Translation (NAT) routers, along with the various restrictions that may be set by your Internet Service Provider.
Most devices have a private IP address (globally, a non-unique address) and require a NAT device that takes care of transforming the private address into a public address (as well as the ports) to access the Internet. In reality, in most cases, two browsers cannot communicate directly since neither of them knows the IP address and port they can use to reach the other.
This is where the Interactive Connectivity Establishment (ICE) technique comes into play to allow WebRTC agents to communicate while abstracting from the complexity of the networks that make up the Internet. ICE will use Session Traversal Utilities for NAT (STUN) and Traversal Using Relays around NAT (TURN) servers to overcome problems caused by firewalls, NAT routers and other potential restrictions.
A STUN server allows the agent to know the network information it is exposing to the outside world, i.e., its public IP address, the port, and the type of NAT router in front of it. This server is, in some ways, equivalent to the well-known Web site, https://www.whatismyip.com/.
A TURN server is an extension to STUN when the latter fails to establish a connection. It will relay the media from one agent to the other and, unlike STUN, will have to be present during the entire communication. TURN is a more demanding operation, and direct communication should always be favoured.
In reality, ICE is an integral part of the communication initialization stage. Here is what our new architecture looks like after adding our STUN and TURN servers:
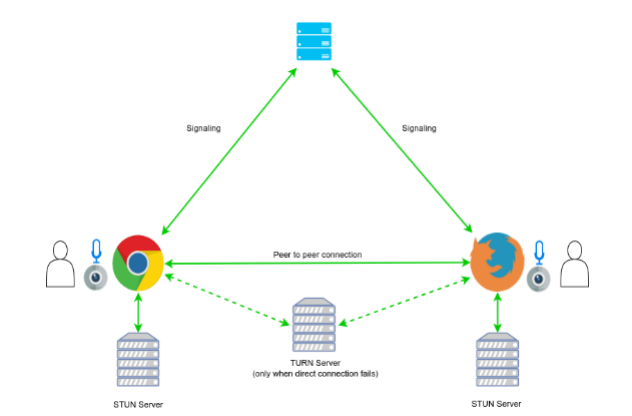
WebRTC architecture with TURN and STUN servers.
Source: WebRTC.ventures: A Guide to WebRTC How it works Part I
Different levels of solutions are available for the use of STUN/TURN servers. You may:
- Use free servers over which you have no control (https://gist.github.com/yetithefoot/7592580, for a brief list)
- Subscribe to a paid service (Twilio, etc.)
- Create your own server by using, for example, an open-source solution, like coturn (https://github.com/coturn/coturn).
The multi-party nature of videoconferencing
So far, we have seen how to connect one peer to another. But what happens when we want to connect more participants, as in a typical videoconference? There are actually three approaches to deploying a multi-party videoconferencing application: Mesh, MCU and SFU.
The Mesh approach
Mesh is a straightforward approach, where each participant sends media to each of the other participants. This approach fails quickly beyond three participants regarding bandwidth and the number of connections. A participant will have to upload their media to each of the other participants and download the media from each.
This is the approach used in most WebRTC tutorials available all over the web. It is an excellent proof of concept but only applicable to a production context if you are explicitly aware of its limitations.
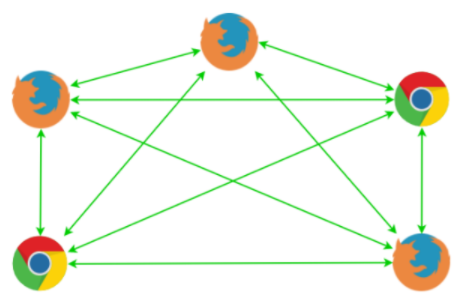
Mesh Model
Source: WebRTC.ventures A Guide to WebRTC — How it works Part II
The MCU model
MCU (Multipoint Conferencing Unit) is the approach in which the different participants will all communicate with a central unit (a server) that will take care of mixing or composing the different streams into a single audio-video stream (in fact, several templates, but only one will be sent to the participants). This is the best approach with respect to network load and number of connections. This approach limits to one incoming and one outgoing connection between the client and the server, no matter the number of participants.
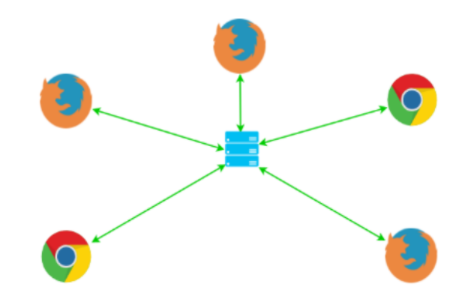
Multipoint Conferencing Unit (MCU) model.
Source: WebRTC.ventures A Guide to WebRTC — How it works Part II
The SFU approach
The third approach, SFU, (Selective Forwarding Unit) allows each participant to send their media to a central server that routes it to the other participants if they request it. This limits the number of uploads to one compared with Mesh but keeps the number of stream downloads equal to the number of participants.
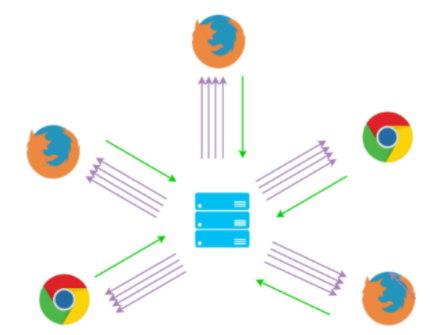
Selective Forwarding Unit (SFU) model.
Source: WebRTC.ventures A Guide to WebRTC — How it works Part II
Choosing the right model for your use-case
Suppose MCU is the most interesting model. In that case, it is important to note that such a central server has to handle all the processing, i.e. receiving, decoding the streams, composing the new stream, re-encoding the different streams and sending. Such processing, taken together, is extremely CPU-intensive. As the size of the video streams increases (4k, but soon 8k), the processing time will increase significantly with this approach, and a large-scale deployment based on the MCU model will require dozens, even hundreds, of additional machines as opposed to SFU.
In fact, the SFU approach is increasingly favoured in the WebRTC context, although different solutions often offer hybrid models. Since WebRTC is multi-stream by nature, the SFU model fits perfectly with this logic: the client receives multiple audio and video streams that it must decode individually and display on the screen. SFU limits the intermediary server to simple and undemanding tasks, such as receiving, selecting and sending the streams.
The pure SFU approach has the disadvantage of being demanding of a participant’s bandwidth as he or she must download several streams. As a result, some SFU approaches offer content encoding and decoding, if only to offer adapted content to participants (adaptive bitrate streaming) and thus maximize the user experience by limiting interruptions.
The other option is to use a codec that supports scalability (H.264 SVC / Scalable VP9) or Simulcast to benefit from a pure SFU architecture with content adaptation. In such an SFU model, each participant uploads an onion of video layers of different qualities, and the server decides which of these layers will be transmitted to which participant (see SVC and Video Communications).
While SFU remains the preferred model due to its low deployment and operating costs compared to MCU, each of the three models is well suited to different use-cases. For example, in the case of videoconferences limited to 3 or even 5 participants, the Mesh model may be perfectly adequate. In a case where the different clients are mobile and have few resources at the CPU and bandwidth levels, MCU is the optimal architecture. A hybrid approach also allows the application to switch from a Mesh model, when a minimal number of participants are connected, to MCU/SFU when the number goes beyond 4 or 5.
Other features you may want
Beyond the possibility of having an infrastructure with the capacity to support multi-party conferences, other features are also attractive and often available in the different products we will see later, such as:
- Recording of audio and video content
- Quality of the video content adapted to each participant
- A text messaging system
- The ability to share files
- Screen sharing
- The ability to make drawings or models in the form of a whiteboard in real-time
- Augmented reality (filters, objects, etc.)
- Integration with different legacy initialization protocols (e.g. SIP)
You will need to determine which of these features you will definitely need, or not, before you can determine the right solution or tool for your application.
Solutions and tools
Whether for the selection of the initialization protocol as such, the implementation of ICE servers (STUN/TURN), the choice of architecture or the different functionalities you intend to offer, different solutions exist and will significantly facilitate the development of your application.
Purely peer-to-peer solution
For a fully P2P (peer-to-peer) architecture, that is, based on the Mesh model, you will need to define an initialization protocol and set up the bypass servers (STUN/TURN). This infrastructure, hosted on-site or not, will still be minimal, and energies will have to be put mainly into the front-end development of the application.
Even in this context, it will be advisable to use an open-source library, given the standard’s current volatility and relative complexity. In this respect, the different libraries available will simplify using the MediaStream and RTCPeerConnection APIs while offering a turnkey initialization method and ensuring cross-browser compatibility as the specification develops.
Among the most interesting at the moment, the following are noteworthy:
- simple-peer: https://github.com/feross/simple-peer
- SimpleWebRTC: https://github.com/andyet/SimpleWebRTC
- adapter.js: https://github.com/webrtc/adapter
On-site (and open-source) media server
To implement an MCU/SFU architecture and have multiple advanced features specific to multiparty video conferencing applications, in addition to having full control over your infrastructure, you will definitely need a media server.
A few tools, in particular, stand out.
- Mature project, supported by Atlassian and with a vast and active community
- License: Apache 2.0
- SFU model with XMPP signalling
- Offers many features including, messaging, screen sharing (via a plugin), file transfer, noise removal in audio streaming, call encryption, etc.
- Jitsi also offers a modern and complete web (React) and mobile (React Native) application
- Connection of SIP participants by Jigasi
- An open-source project largely dropped in 2017 (after it was acquired by Twilio), but the project got a new lease on life in 2018 with the establishment of a new development team
- License: Apache 2.0
- Hybrid SFU/MCU model
- Offers recording, transcoding, video content adaptation, etc.
- Offers client libraries/SDKs to facilitate interactions with the server (Java and JavaScript clients)
- Supports multiple initialization protocols
- A relatively new project based around a small community
- License: ISC
- A new pure SFU approach developed with Node.js/ES6
- Handles the multimedia layer only, so it does not include an initialization protocol
- Offers multi-stream audio/video
- Offers a JavaScript client library
- No stream recording and generally few features compared to others
Note. The Janus ( GPLv3) and Medooze (GPLv2) licenses did not include these features in our situation, so we didn’t look particularly closely at them.
Communications Platform-as-a-Service
Various paid products offered as Communications Platform-as-a-Service (CPaaS) also exist and offer a complete, stable and scalable infrastructure for developing your WebRTC-based videoconferencing application. These solutions also offer a range of advanced features on the industry’s leading edge.
Among the most mature and widely used, we would recommend:
Conclusion
Our expertise in this emerging field is admittedly limited. However, it is clear from the information available that the implementation of a WebRTC videoconferencing application will be greatly facilitated by:
- Arming your development team with network expertise
- Defining your use-cases and functionality
- Carefully considering the different architecture models according to your needs
- Using the tools available
And a final recommendation: make time to enjoy life!












{kind=link}
{kind=link}